스크래피 아키텍쳐 번역
by Sooyoung
Architecture overview
Scrapy Architecture Overview 를 번역한 것입니다. 개인 공부를 위한 번역이기 때문에 미흡한 점이 많습니다. 미리 양해 부탁드립니다.
이 문서는 스크래피의 아키텍쳐와 스크래피 컴포넌트들이 어떻게 상호작용하는지를 설명합니다.
Overview
아래의 다이어그램은 스크래피 시스템 내에서 발생하는 데이터의 흐름의 개요와 (초록색 화살표) 아래의 컴포넌트들을 지니고 있는 스크래피 아키텍쳐를 보여줍니다. 컴포넌트들의 간략한 설명은 컴포넌트들에 대한 더 자세한 설명을 위해 아래 링크에 포함되어 있습니다. 데이터 흐름 또한 아래에 설명되어 있습니다.
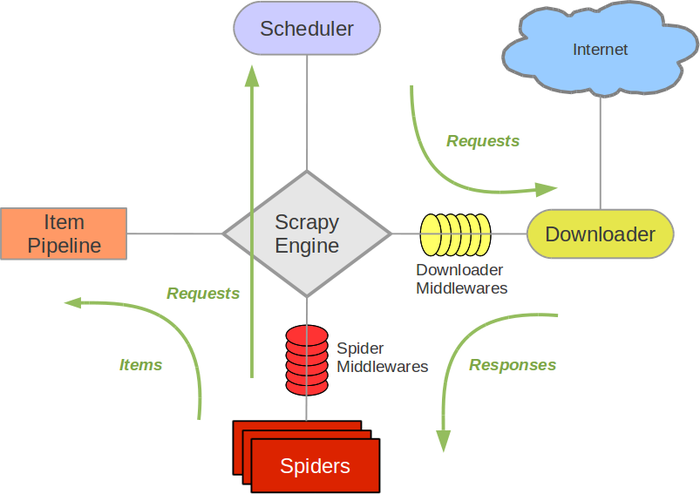
Components
### Scrapy Engine 이 앤진은 시스템의 모든 컴포넌트들 사이의 데이타 흐름을 제어하고 특정한 액션이 발생했을때 이벤트를 실행시키는 책임을 가지고 있습니다. 아래 데이터 흐름(Data Flow) 부분에서 더 자세한 설명을 보세요.
Scheduler
스케줄러는 엔진으로부터 요청을 받고, 엔진으로 부터 요청이 왔을때 이들을 큐에 넣습니다.
Downloader
다운로더는 웹 페이지들을 가지고오고 웹 페이지를 엔진에 넘겨 차례로 이들을 스파이더에 넣는 책임을 가지고 있습니다.
Item Pipeline
아이템 파이프라인은 스파이터에 의해서 아이템들이 추출하고나면 아이템들을 처리할 책임을 가지고 있습니다. 아이템 파이프라인의 전형적인 임무는 영속성(데이타베이스에 아이템을 저장하는것과 같은), 유효성 검사, cleansing(정화?)를 포함 합니다. 더 많은 정보는 Item Pipeline 를 보세요.
Downloader middlewares
다운로더 미들웨어는 엔진과 다운로드사이의 구체적인 고리이입니다. 다운로드 미들웨어는 또한 엔진에서 다운로더까지 통과하는 요청들과 다운로더에서 엔진을 통과하는 응답들을 처리합니다. 다운로드 미들웨어는 Custom code를 넣음으로써 스크래피의 기능들 확장하기위한 편리한 메카니즘을 제공합니다. 더 자세한 정보는 Downloader middlewares를 보세요
Spider middlewares
스파이더 미들웨어는 엔진과 스파이더 사이에 있는 구제적인 고리이며 스파이더의 인풋(respnses) 와 아웃풋(item and requests)를 처리할수 있습니다. 스파이더 미들웨어는 Custom code를 넣음으로써 스크래피의 기능들 확장하기위한 편리한 메카니즘을 제공합니다. 더 자세한 정보는 Spider middlewares를 보세요.
Data flow
스크래피에서 데이터의 흐름은 이것의 실행 엔진에 의해서 제어됩니다. 그리고 아래와 같습니다.
- 엔진은 도메인을 열고, 그 도메인을 다루는 특정 스파이더를 위치시키고 그 스파이더에게 첫번째 URLs을 클롤링하라고 요청합니다.
- 엔진은 그 스파이더로부터 크롤링할 첫 URL을 얻고, 요청으로써 스케줄러에 그들을 등록합니다. (The Engine gets the first URLs to crawl from the Spider and schedules them in the Scheduler, as Requests.)
- 그리고 나서 엔진은 스케줄러에게 다음 URLs을 크롤링하라고 요청합니다.
- 스케줄러는 엔진에게 크롤링할 다음 URLs을 반환하고 엔진은은 이러한 URLs을 다운로더 미들웨어를 통해(request 방향) 다운로더에게 보냅니다.
- 특정 페이지가 다운로딩을 마치게 되면 다운로더는 a Response(그 페이지를 가지고있는)를 생성하고, 이 response를 다운로드 미들웨어를 통해서 (response 방향) 엔진에게 보냅니다.
- 그 다음 엔진은 다운로더로부터 그 response를 받아서 이 response를 처리하기위해 스파이터 미들웨어를 통해(input 방향) 스파이더에게 보냅니다.
- 스파이더는 이 response를 처리하고 스크랩된 아이템들과 다음에 이뤄질 새로운 request를 반홥합니다.
- 엔진은 스파이더로부터 반환된 스크랩된 아입을 아이템 파이브라인에 보내고, 스파이터로부터 반환된 Request를 스케줄러에 보냅니다.
- 이러한 처리는 스케줄러로부터 더 이상의 request가 없을때까지 반복되고, 처리가 완료되면 엔진은 이 도메인을 끝냅니다.
Subscribe via RSS